いろいろな投票法があるんですね。とりあえず票移動方式で考えてみました。
どういう投票パターンが、もし知名度があったら、多くの票数になる可能性があるのかを考えてみました。特定候補者から、票が移動しているより、多くの候補者から、票が移動している人のほうが、知名度があがれば、票が増えると考えました。その場合、グラフ理論のなかでは、ページランクという指標があっていそうです。
投票パターンを
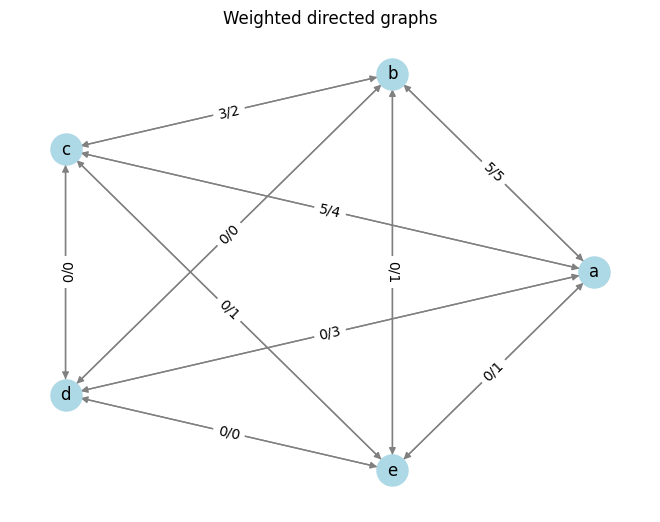
[[0, 5, 5, 0, 0],
[5, 0, 3, 0, 0],
[4, 2, 0, 0, 0],
[3, 0, 0, 0, 0],
[1, 1, 1, 0, 0]]
(横方向の和が加算される票(プラス票)、縦方向の和が減算される票(マイナス票))
として、固有ベクトル中心性と、ページランクを比較してみました。
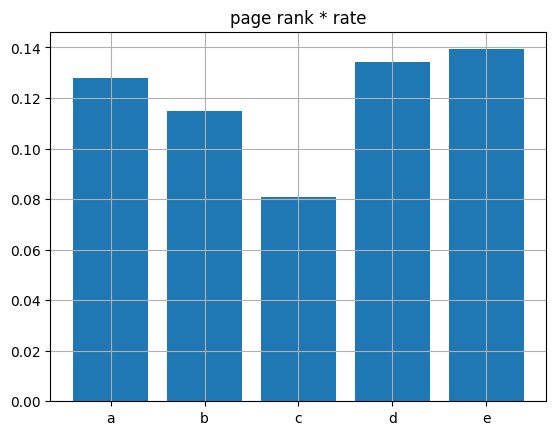
候補者dは候補者aからのみ票が移動していませんが、候補者eは候補者a,b,cから票が移動しています。なので、固有ベクトル中心性では候補者eが最下位ですが、ページランクでは候補者dが最下位になっています。絶対的票数がすくないと、上位にはならないです。ページランクにプラス票 / (プラス票 + マイナス票)をかけることを考えました。マイナス票が少ないほうが有利になるように考えました。
今回の例では、候補者d,eはマイナス票は0なので、いっきに1,2位に上がっています。当選者は候補者eになります。多くの候補者から票がきていて、嫌われていないということなで、いろいろな層から支持され、知名度があれば票数が増える候補者が選ばれたと考えられませんでしょうか?今回の例はかなり恣意的に投票パターンを決めているので、実際にどうかは、もっと検討が必要だとはおもいますが。
一応計算に使用舌コードを記載しておきます。networkxで計算しています。
import numpy as np
import matplotlib.pyplot as plt
import networkx as nx
# グラフ表示
def calculate_eigenvector_centrality(graph):
# グラフの描画
# pos = nx.spring_layout(graph)
pos = nx.circular_layout(graph)
nx.draw(graph, pos, with_labels=True, node_color='lightblue', node_size=500, edge_color='gray', arrows=True)
# 辺の重みを表示 (両方向を区別)
edge_labels = {}
for u, v, data in graph.edges(data=True):
edge_labels[(u, v)] = data['weight']
if (v, u) in graph.edges():
edge_labels[(u, v)] = f"{data['weight']}/{graph[v][u]['weight']}" # 両方向の重みを表示
nx.draw_networkx_edge_labels(graph, pos, edge_labels=edge_labels)
plt.title("Weighted directed graphs")
plt.show()
# main ------------------------------
# 票の移動量設定
A = np.array([
[0, 5, 5, 0, 0],
[5, 0, 3, 0, 0],
[4, 2, 0, 0, 0],
[3, 0, 0, 0, 0],
[1, 1, 1, 0, 0]
])
num, _ = A.shape
# 候補者名
cname = ['a', 'b', 'c', 'd', 'e']
# for networkX
G = nx.DiGraph()
for i in range(num):
for j in range(num):
if i!=j:
G.add_edge(cname[i], cname[j], weight=A[j, i])
in_degree = G.in_degree(weight='weight')
out_degree = G.out_degree(weight='weight')
dout_degree = dict(out_degree)
name = []
sum01 = [] # プラス票の総和
sum02 = [] # プラス票 - マイナス票
rate = {} # プラス票/(プラス票 + マイナス票)
for key, value in in_degree:
name.append(key)
sum01.append(value)
sum02.append(value-dout_degree[key])
rate[key] = np.double(value)/np.double(value+dout_degree[key])
# 固有ベクトル中心性計算
eigenvector_centrality = nx.eigenvector_centrality(G, weight='weight')
# ページランク計算
pagerank = nx.pagerank(G, weight='weight')
# ページランク * プラス票 / (プラス票 + マイナス票) 計算
pagerankrate = {}
for key, value in pagerank.items():
pagerankrate[key] = pagerank[key]*rate[key]
# 図表示
calculate_eigenvector_centrality(G)
plt.bar(name, sum01)
plt.grid()
plt.title('sum')
plt.show()
plt.bar(name, sum02)
plt.grid()
plt.title('Addition and subtraction')
plt.show()
plt.bar(eigenvector_centrality.keys(), eigenvector_centrality.values())
plt.grid()
plt.title('eigenvector centrality')
plt.show()
plt.bar(pagerank.keys(), pagerank.values())
plt.grid()
plt.title('page rank')
plt.show()
plt.bar(pagerankrate.keys(), pagerankrate.values())
plt.grid()
plt.title('page rank * rate')
plt.show()